All Categories
Featured
Table of Contents
- – Optimizing Learning Paths For Data Science Int...
- – Using Python For Data Science Interview Challe...
- – Using Ai To Solve Data Science Interview Prob...
- – Most Asked Questions In Data Science Interviews
- – Key Behavioral Traits For Data Science Inter...
- – Key Data Science Interview Questions For Faang
Amazon now commonly asks interviewees to code in an online record file. However this can vary; maybe on a physical white boards or a virtual one (Exploring Data Sets for Interview Practice). Examine with your employer what it will be and practice it a great deal. Since you know what questions to expect, let's concentrate on just how to prepare.
Below is our four-step prep plan for Amazon information researcher candidates. Before investing tens of hours preparing for a meeting at Amazon, you need to take some time to make certain it's actually the right firm for you.
, which, although it's developed around software application advancement, must provide you an idea of what they're looking out for.
Note that in the onsite rounds you'll likely have to code on a white boards without having the ability to execute it, so practice creating via problems theoretically. For device learning and data concerns, supplies on-line training courses created around analytical likelihood and various other valuable topics, a few of which are free. Kaggle Supplies cost-free courses around introductory and intermediate equipment learning, as well as information cleansing, information visualization, SQL, and others.
Optimizing Learning Paths For Data Science Interviews
Lastly, you can publish your very own concerns and go over subjects most likely to come up in your interview on Reddit's statistics and artificial intelligence threads. For behavior interview inquiries, we advise discovering our detailed approach for addressing behavior questions. You can after that utilize that technique to exercise responding to the example concerns supplied in Section 3.3 above. Make certain you contend least one story or example for each and every of the concepts, from a large range of settings and projects. Finally, a terrific method to exercise all of these various sorts of concerns is to interview on your own out loud. This might appear unusual, yet it will considerably improve the method you connect your answers during a meeting.

One of the major difficulties of data researcher interviews at Amazon is communicating your different responses in a method that's very easy to comprehend. As a result, we highly advise practicing with a peer interviewing you.
They're unlikely to have expert understanding of meetings at your target company. For these factors, many prospects avoid peer simulated interviews and go directly to simulated meetings with a professional.
Using Python For Data Science Interview Challenges
That's an ROI of 100x!.
Commonly, Data Scientific research would certainly focus on maths, computer system science and domain know-how. While I will briefly cover some computer system science fundamentals, the bulk of this blog site will mainly cover the mathematical essentials one may either require to clean up on (or also take an entire course).
While I understand most of you reading this are much more math heavy by nature, realize the mass of data scientific research (attempt I say 80%+) is accumulating, cleaning and handling information right into a valuable type. Python and R are one of the most preferred ones in the Data Scientific research room. I have likewise come across C/C++, Java and Scala.
Using Ai To Solve Data Science Interview Problems

Usual Python collections of option are matplotlib, numpy, pandas and scikit-learn. It is typical to see the majority of the data researchers being in a couple of camps: Mathematicians and Data Source Architects. If you are the second one, the blog won't assist you much (YOU ARE CURRENTLY AMAZING!). If you are amongst the first team (like me), possibilities are you feel that composing a double embedded SQL query is an utter headache.
This might either be accumulating sensor information, parsing websites or performing surveys. After collecting the information, it requires to be changed into a functional kind (e.g. key-value store in JSON Lines data). Once the information is collected and put in a functional style, it is necessary to perform some information top quality checks.
Most Asked Questions In Data Science Interviews
However, in instances of fraud, it is extremely common to have hefty class imbalance (e.g. only 2% of the dataset is actual fraud). Such information is necessary to pick the proper selections for function engineering, modelling and version examination. To find out more, examine my blog site on Scams Discovery Under Extreme Class Inequality.

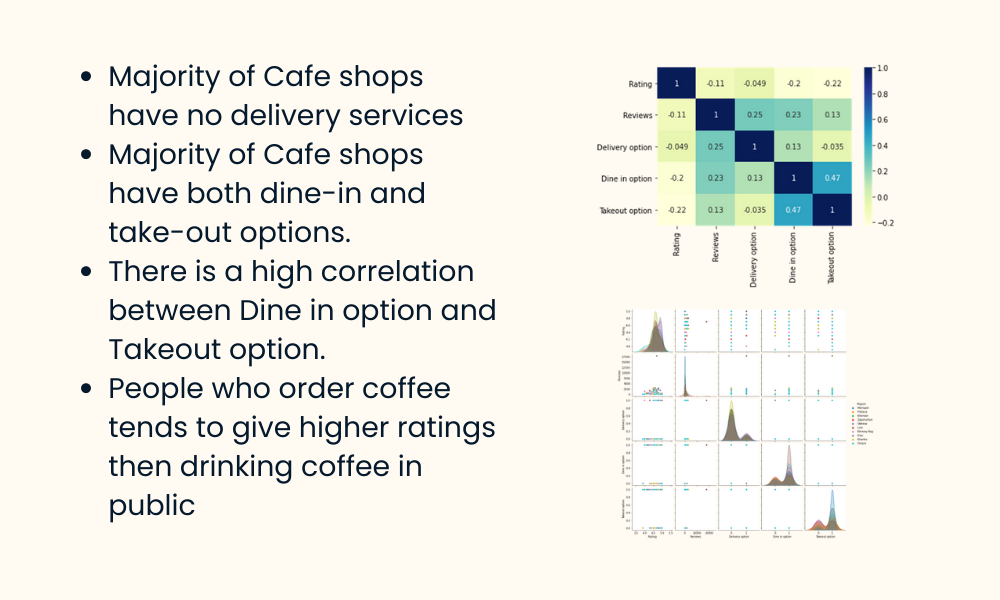
In bivariate analysis, each function is compared to other features in the dataset. Scatter matrices permit us to find hidden patterns such as- features that must be engineered together- features that might need to be removed to avoid multicolinearityMulticollinearity is really an issue for multiple designs like straight regression and therefore requires to be taken treatment of accordingly.
In this section, we will certainly explore some common attribute engineering methods. At times, the feature by itself might not provide valuable details. Think of making use of internet usage data. You will certainly have YouTube customers going as high as Giga Bytes while Facebook Messenger individuals use a number of Mega Bytes.
An additional issue is the use of categorical values. While specific worths are usual in the information scientific research globe, understand computer systems can just comprehend numbers.
Key Behavioral Traits For Data Science Interviews
At times, having too numerous thin dimensions will interfere with the efficiency of the version. For such situations (as frequently performed in picture recognition), dimensionality decrease formulas are utilized. A formula frequently used for dimensionality decrease is Principal Components Evaluation or PCA. Discover the mechanics of PCA as it is additionally one of those topics amongst!!! For even more details, look into Michael Galarnyk's blog site on PCA utilizing Python.
The common categories and their sub groups are explained in this area. Filter techniques are typically used as a preprocessing action.
Common approaches under this group are Pearson's Relationship, Linear Discriminant Evaluation, ANOVA and Chi-Square. In wrapper approaches, we try to use a part of features and train a model utilizing them. Based upon the reasonings that we draw from the previous design, we decide to include or remove features from your part.
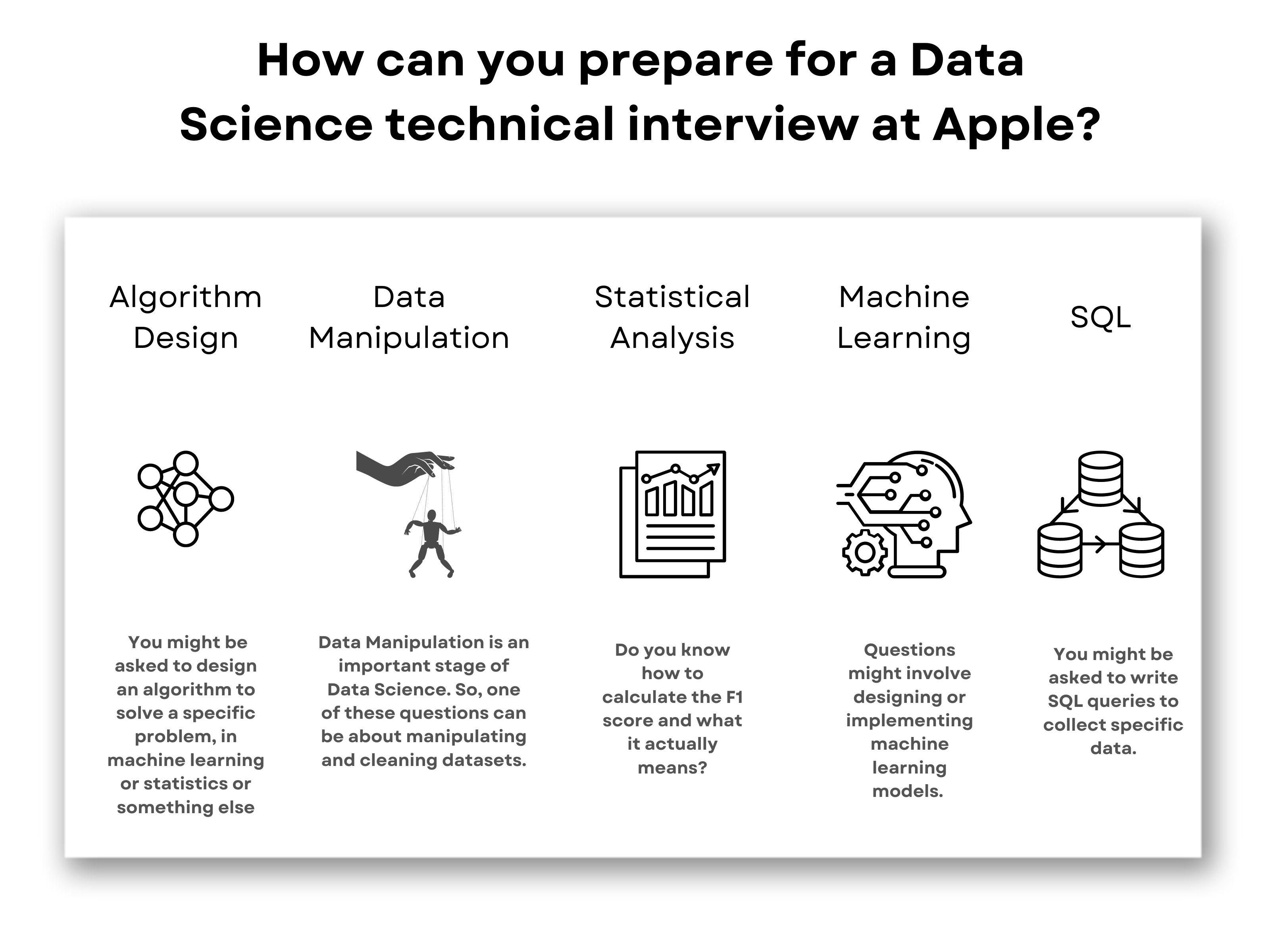
Key Data Science Interview Questions For Faang
Usual techniques under this group are Onward Option, Backward Elimination and Recursive Feature Removal. LASSO and RIDGE are typical ones. The regularizations are provided in the formulas below as referral: Lasso: Ridge: That being said, it is to comprehend the technicians behind LASSO and RIDGE for meetings.
Managed Knowing is when the tags are available. Without supervision Learning is when the tags are unavailable. Obtain it? SUPERVISE the tags! Word play here meant. That being stated,!!! This blunder suffices for the recruiter to terminate the interview. Likewise, one more noob error individuals make is not stabilizing the functions before running the model.
. General rule. Direct and Logistic Regression are one of the most basic and generally made use of Artificial intelligence formulas out there. Before doing any kind of analysis One usual meeting slip individuals make is starting their analysis with a much more intricate model like Neural Network. No uncertainty, Semantic network is highly precise. Standards are vital.
{kind=link}
Table of Contents
- – Optimizing Learning Paths For Data Science Int...
- – Using Python For Data Science Interview Challe...
- – Using Ai To Solve Data Science Interview Prob...
- – Most Asked Questions In Data Science Interviews
- – Key Behavioral Traits For Data Science Inter...
- – Key Data Science Interview Questions For Faang
Latest Posts
Netflix Software Engineer Interview Guide – Insider Advice
How To Answer Algorithm Questions In Software Engineering Interviews
The 10 Types Of Technical Interviews For Software Engineers
More
Latest Posts
Netflix Software Engineer Interview Guide – Insider Advice
How To Answer Algorithm Questions In Software Engineering Interviews
The 10 Types Of Technical Interviews For Software Engineers